Your AI Agent
Clear as Glass
Detect silent production failures
and fix them
Track every interaction, LLM call, agent chain of thought, tool usage.
See user counts, costs, and latency.
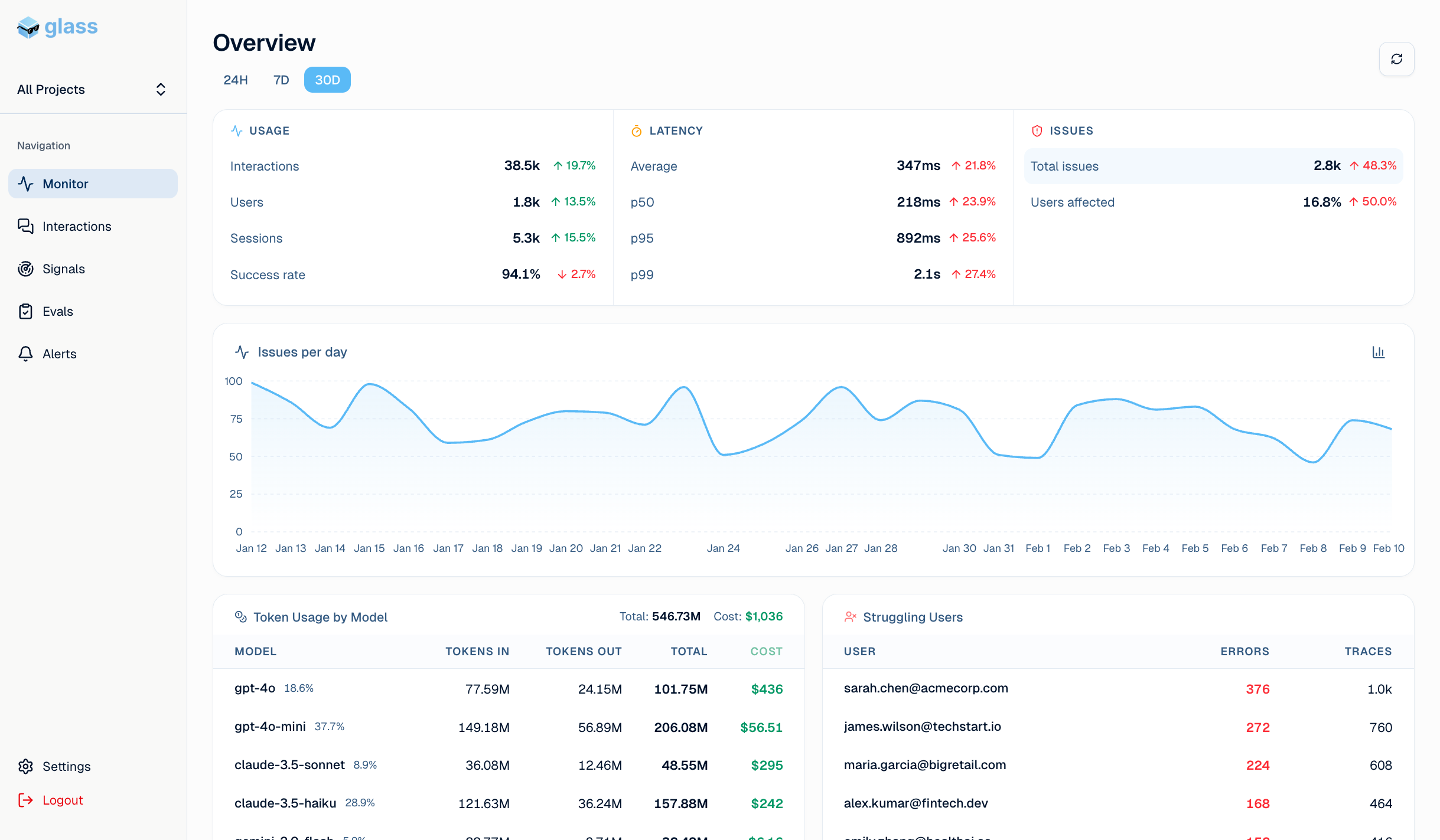
Drill into every interaction with a full trace view.
See each LLM call, tool use, and step in the agent's chain of thought.

Failures and misbehaviors are caught automatically and classified.
Their impact on users is measured and reported.

Every classified failure becomes an evaluation test case.
Build a growing regression suite that fixes issues before they reach users.

Daily production insights delivered to your team channel.
Stay on top of your AI agent's health without checking dashboards.

You can't keep track of all failures
across thousands of interactions.
Monitoring tools give you blank metrics
Glass surfaces misbehaviors and helps you fix them
Catch issues 10x faster
Automated classification surfaces problems the moment they appear. No more digging through logs.
Reduce user churn from AI failures
Quantify the cost of every failure type and fix the ones that matter most to your bottom line.
Ship changes with confidence
Run every change against a battle-tested eval suite before it reaches production.
No-Sweat Start
Start with observability in 2 minutes.
Then unlock the full flywheel.
# Install the SDK # pip install glass-ai import os from glass-ai import init, interaction, traced init( api_key=os.environ.get("GLASSAI_API_KEY"), ) # Wrap your LLM interactions with interaction(conversation_params) as trace: # ... your LLM code here ... # Use decorators for tool calls or other steps in your code @traced def search_database(query: str): return db.search(query)
Frequently asked questions
GlassAI works with any LLM-powered agent — whether you're using OpenAI, Anthropic, Mistral, or an open-source model. We support multi-step pipelines, tool-calling agents, RAG workflows, and custom orchestration frameworks.
Under 2 minutes. Install our SDK, add one line of instrumentation to your agent, and you'll start seeing traces immediately — no infrastructure changes required.
We only store the trace data you explicitly send us — inputs, outputs, and metadata from your agent runs. You control what gets logged and can mask or redact sensitive fields before they leave your environment.
Security is a top priority for us. We are currently in the process of obtaining SOC 2 Type II and ISO 27001 certifications. In the meantime, all data is encrypted in transit (TLS 1.2+) and at rest (AES-256), and we follow industry best practices for access control and vulnerability management. Enterprise customers can request our security documentation and sign a DPA.
Yes. We offer a self-hosted option for teams with strict data residency or on-premise requirements. Reach out to us to discuss your setup.
The free plan includes full observability for up to 10,000 traces/month. Paid plans unlock higher volume, anomaly detection alerts, eval pipelines, team collaboration, and priority support. See the pricing page for details.
Regain trust in your agent
Start monitoring your AI agents for free in under 2 minutes.